728x90
Activation Function
Neural Network의 각 layer는 Activation Function을 사용하여 layer를 통과한 output을 변환하고,
이 변환된 output을 다음 layer로 전달합니다.
Activation Function은 비선형성을 추가하여 Neural Network가 복잡한 패턴과 관계를 학습할 수 있도록 해줍니다.

Activation Function을 사용하는 이유
Activation Function이 없으면 Neural Network의 모든 layer는 선형 변환만을 수행하게 되며,
이는 Linear Regression과 같은 단순한 모델과 다른 점이 없습니다.
결과적으로, DNN을 구성하더라도 복잡한 문제를 해결할 수 없습니다.
즉, layer를 겹겹히 쌓더라도 Activation Function이 없다면
결론적으로 Input 과 Output은 단순한 선형 변환일 뿐인 것입니다.
실세계에서 선형적으로 해석되는 것은 극히 일부이며,
이 때문에 Activation Function이 없는 Neural Network로는
실세계의 복잡한 패턴이나 비선형 관계를 학습할 수가 없습니다.
주요 Activation Function
1. Sigmoid Function
- 출력 범위: (0, 1)
- 장점: 출력이 0과 1 사이에 있으므로 확률을 표현할 때 유용.
- 단점: 큰 음수나 양수에서 기울기가 거의 0에 가까워지는 Vanishing Gradient(기울기 소실) 문제 발생.


import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
2. Tanh Function
- 출력 범위: (-1, 1)
- 장점: 출력이 0을 중심으로 대칭적이므로 학습이 더 빠르고, Sigmoid 함수보단 기울기 소실 문제가 덜함.
- 단점: 여전히 극단적인 값에서 기울기 소실 문제가 발생할 수 있음.


def tanh(x):
return np.tanh(x)
3. ReLU (Rectified Linear Unit)
- 출력 범위: [0, ∞)
- 장점: 계산이 간단하고, 기울기 소실 문제를 해결. 양수 입력에 대해 기울기가 1이므로 학습이 빠름.
- 단점: 입력이 0 이하일 때 기울기가 0이 되어 Dead Neurons 문제 발생.


def relu(x):
return np.maximum(0, x)
4. Leaky ReLU
- 출력 범위: (-∞, ∞)
- 장점: 음수 입력에 대해서도 작은 기울기를 유지하여 ReLU의 Dead Neurons 문제를 해결.


def leaky_relu(x, alpha=0.01):
return np.where(x > 0, x, alpha * x)
5. Softmax
- 출력 범위: (0, 1), 각 출력의 합은 1
- 주로 다중 Class 분류 문제에서 각 Class에 대한 확률을 계산하는 데 사용됨.

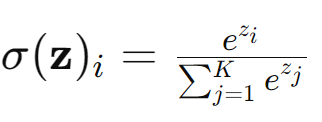
def softmax(x):
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum(axis=0)
728x90
반응형
'Machine Learning > ML DL' 카테고리의 다른 글
| ResNet 이란 무엇인가? (0) | 2024.07.09 |
|---|