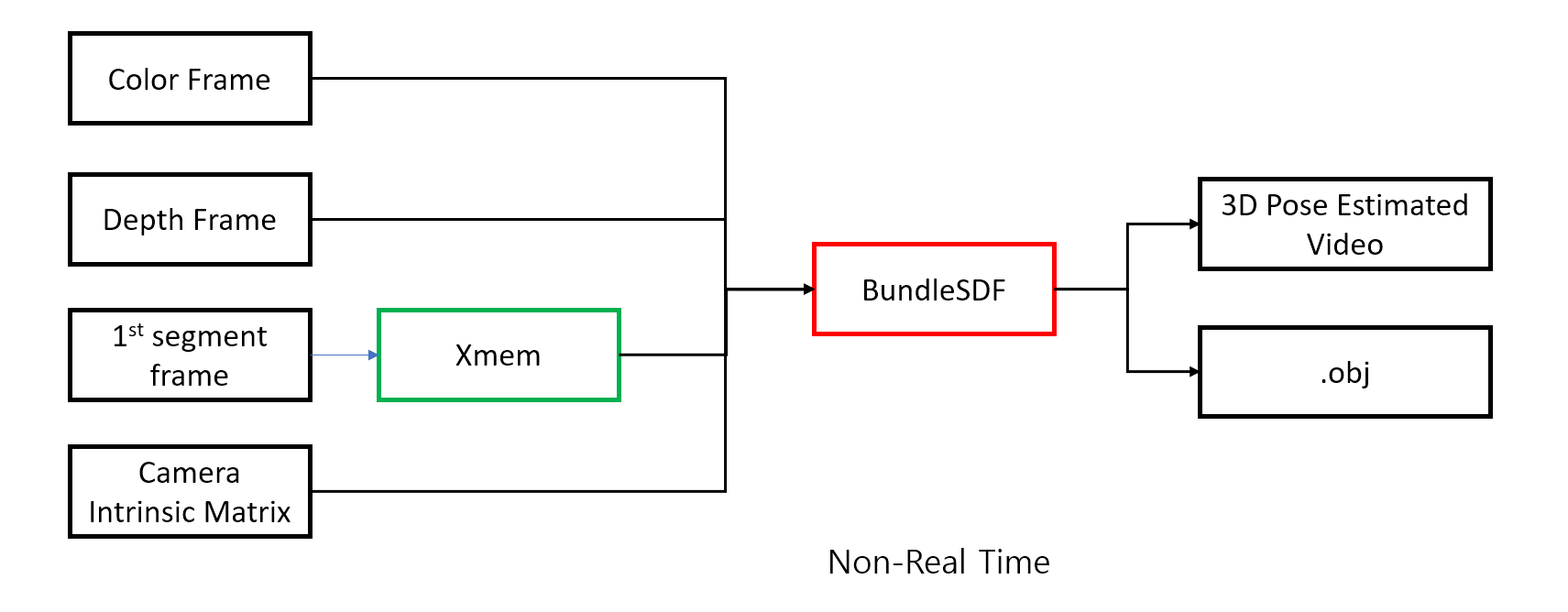
BundleSDF는 RGB-D video input과 Camera Intrinsic Matrix, XMem의 Object Segmentation을 이용하여
Segment Object의 3D Pose Estimation 과 3D reconstruction 을 수행할 수 있는 방식입니다.
추가 정보는 아래 글들에서 확인하시기 바랍니다.
[논문 리뷰] BundleSDF: Neural 6-DoF Tracking and 3D Reconstruction of Unknown Objects
Unknown object에 대해 3D Pose Estimation 과 Object SLAM 기술이 동시에 가능한 BundleSDF에 대해서 살짝 찍먹해보았는데요. 저도 완전히 이해하진 못했지만 간단하게 Input과 Output의 흐름과 사용된 방식들을
cobang.tistory.com
BundleSDF: Neural 6-DoF Tracking and 3D Reconstruction of Unknown Objects
We present a near real-time method for 6-DoF tracking of an unknown object from a monocular RGBD video sequence, while simultaneously performing neural 3D reconstruction of the object. Our method works for arbitrary rigid objects, even when visual texture
bundlesdf.github.io
아래 공식 Github를 따라 실제로 BundleSDF 예제를 수행해보았습니다.
GitHub - NVlabs/BundleSDF: [CVPR 2023] BundleSDF: Neural 6-DoF Tracking and 3D Reconstruction of Unknown Objects
[CVPR 2023] BundleSDF: Neural 6-DoF Tracking and 3D Reconstruction of Unknown Objects - GitHub - NVlabs/BundleSDF: [CVPR 2023] BundleSDF: Neural 6-DoF Tracking and 3D Reconstruction of Unknown Objects
github.com
먼저 BundleSDF git을 clone 시킵니다.
cd
git clone https://github.com/NVlabs/BundleSDF.git
pre-trained Segmentation Network를 다운로드 합니다.
https://drive.google.com/file/d/1MEZvjbBdNAOF7pXcq6XPQduHeXB50VTc/view
XMem-s012.pth
drive.google.com
pre-trained LoFTR 인 outdoor_ds.ckpt 를 다운로드 합니다.
https://drive.google.com/file/d/1M-VD35-qdB5Iw-AtbDBCKC7hPolFW9UY/view?usp=sharing
outdoor_ds.ckpt
drive.google.com
BundleSDF/BundleTrack에 XMem/saves 디렉토리를 만듭니다.
그리고 다운로드한 XMem-s012.pth 파일을 옮겨줍니다.

마찬가지로 outdoor_ds.ckpt 파일도 BundleTrack/LoFTR 디렉토리에서
weights 디렉토리를 만들고 옮겨줍니다.

그리고 결과 파일이 저장될 디렉토리를
result 라는 이름으로
BundleSDF 디렉토리에 만들어주었습니다.
이제 작업 환경 구성을 위해 docker 설치해야 합니다.
아래 글을 참조하시기 바랍니다.
nvidia docker까지 모두 설치되신 분들은 아래 과정을 skip 하시기 바랍니다.
docker 설치 + NVIDIA docker 설치 + docker 사용법
Docker ? Docker는 컨테이너화를 사용하는 오픈 소스 플랫폼으로, 애플리케이션을 가볍고, 격리된 환경인 컨테이너 내에서 실행할 수 있게 해줍니다. 컨테이너는 운영 체제(OS) 레벨의 가상화를 제공
cobang.tistory.com
다시 돌아와서 docker를 다운로드 받습니다.
cd ~/BundleSDF/docker
docker build --network host -t nvcr.io/nvidian/bundlesdf .
docker가 빌드되면서 시간이 상당히 걸립니다.
중간에 중단되더라도, 다시 명령을 입력하면 재개할 수 있습니다.
설치가 완료되면 실행시킵니다.
bash run_container.sh
그럼 터미널이 container에서 활성화됩니다.

이제 BundleSDF가 있는 경로까지 들어가주겠습니다.
username을 사용자 명에 맞게 수정해주세요.
cd /home/username/BundleSDF
그리고 다음 명령을 실행합니다.
bash build.sh
그리고 아래 링크를 통해 test 데이터를 받고,
BundleSDF 디렉토리에 압축을 풀어줍니다.
https://drive.google.com/file/d/1akutk_Vay5zJRMr3hVzZ7s69GT4gxuWN/view
2022-11-18-15-10-24_milk.zip
drive.google.com
이렇게 custom data를 분석하기 위해서는 아래 파일들이 필수 input으로 필요합니다.
root
├──rgb/ (PNG files)
├──depth/ (PNG files, stored in mm, uint16 format. Filename same as rgb)
├──masks/ (PNG files. Filename same as rgb. 0 is background. Else is foreground)
└──cam_K.txt (3x3 intrinsic matrix, use space and enter to delimit)rgb는 rgb 이미지 집합
depth는 depth 이미지 집합
mask는 mask 이미지 집합
cam_K.txt는 camera intrinsic matrix가 담깁니다.
이 때 mask 는 논문에서 initial frame만 있으면 된다고 했는데
왜 전체 이미지에 대한 mask가 존재하는지 의문을 가졌습니다.
게다가 online 추적이 된다고 하는데, 미래의 frame 에 대한 mask가 존재하는 것은 말이 안됩니다.
조금 더 공부를 해보니,
원래 여기서 사용했던 XMem 이라는 기술 자체가
Initial frame 을 Anchor 프레임으로 설정하고 이를 통해 Segmentation을 수행합니다.
그러나 저자는 license 이슈로 인해 Github에 업로드한 코드에 대해서는
이를 코드에서 바로 initial frame을 XMem을 통해 수행하지 못하고,
최종적으로 XMem 을 통해 생성된 frame을 다 저장해두고 코드를 돌렸습니다.
이를 segmentation_utils.py에 추가해서 수행할 수 있다고 하는데,
결론적으로 저는 하진 않았습니다.
이와 같은 결정에 대해서는 이 글의 말미에서 설명드리겠습니다.
이제 BundleSDF 를 이용하여 pose를 얻고 결과를 reconstruction 합니다.
미리 말씀드리지만, 일단 실행하기 전에 GPU memory 를 nvidia-smi 명령어를 통해 확인해보시고
10GB 부근이라면 Batch size를 줄이셔야 합니다.
그 이유는 milk dataset의 경우 1932개의 이미지가 있는데, 이것이 모두 분석될 때 까지 계속 반복하게 됩니다.
저는 300번대 정도의 이미지에서 다음과 같은 에러가 뜨면서 Runtime Error 가 발생했습니다.
RuntimeError: Unable to find a valid cuDNN algorithm to run convolution
개발하신 분의 코멘트를 좀 확인해보았는데,
https://github.com/NVlabs/BundleSDF/issues/58
제 NVIDIA GeForce RTX 2080 Ti GPU 메모리가 11GB 라서 발생한 문제같습니다.
저는 loftr_wrapper.py 의 70번째 line인 Batch 사이즈를 8으로 줄여서 시도해보았는데, 성공했습니다.
자신의 GPU에 맞게 잘 수정해서 학습시키시길 바랍니다.
아래 명령을 실행해 BundleSDF를 작동시킵니다.
python run_custom.py --mode run_video --video_dir /home/username/BundleSDF/2022-11-18-15-10-24_milk --out_folder result --use_segmenter 1 --use_gui 1 --debug_level 2
이 때 처음엔 ImportError가 났습니다.
GLIBCXX_3.4.29 가 없다고 하네요.
scipy 버전 변경으로 해결했습니다.
pip uninstall scipy
pip install scipy==1.8.1
다시 실행시킵니다.
python run_custom.py --mode run_video --video_dir /home/username/BundleSDF/2022-11-18-15-10-24_milk --out_folder result --use_segmenter 1 --use_gui 1 --debug_level 2
저는 다음과 같은 에러가 다시 발생했습니다.
import gridencoder
ModuleNotFoundError: No module named 'gridencoder'
터미널에 아래 경로를 설정해주어 해결했습니다.
export PYTHONPATH=/home/mona/BundleSDF/build:$PYTHONPATH
export PYTHONPATH=$PYTHONPATH:/home/mona/BundleSDF/mycuda
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/opt/conda/envs/py38/lib/python3.8/site-packages/torch/lib
다시 실행 명령을 입력하면
아래와 같은 창이 뜨며 분석과 함께 mesh가 형성되는 모습을 gui로 확인할 수 있습니다.
가장 위는 첫번째 이미지고
두번째는 분석된 이미지 프레임이 변화되며 나타납니다.
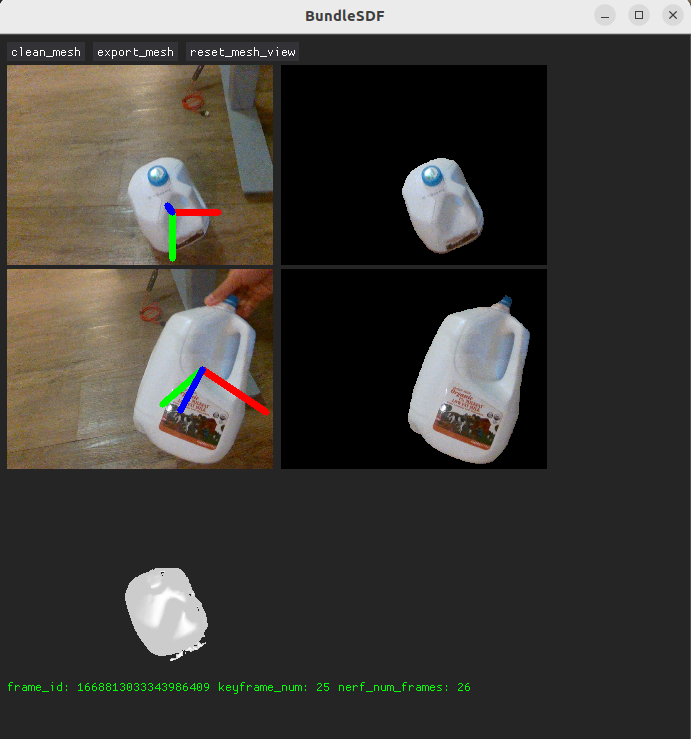
우유통을 잡고 돌릴 수 있습니다.
반복적으로 학습이 이루어집니다.

이미지 프레임 전체를 다 분석할 때 까지 돌아갑니다.

분석이 완료되고 아래와 같이 여러 결과 파일들이 생성되었습니다.
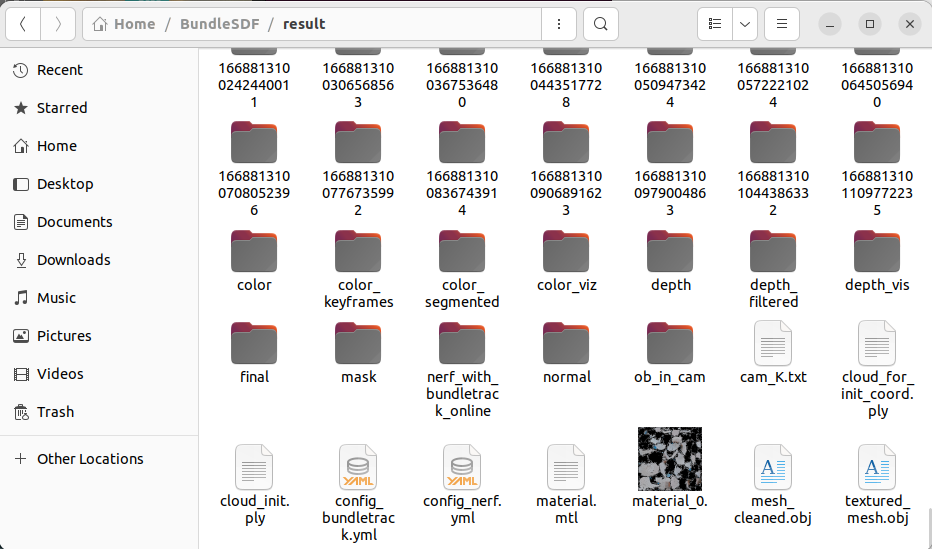
이제 그 다음 작업을 수행해보겠습니다.
이번엔 mesh의 refinement를 수행합니다.
python run_custom.py --mode global_refine --video_dir /home/hslim/BundleSDF/2022-11-18-15-10-24_milk --out_folder result
그리고 최종적으로 결과를 이용하여 3d box를 그립니다.
python run_custom.py --mode draw_pose --out_folder result결과를 확인해보겠습니다.
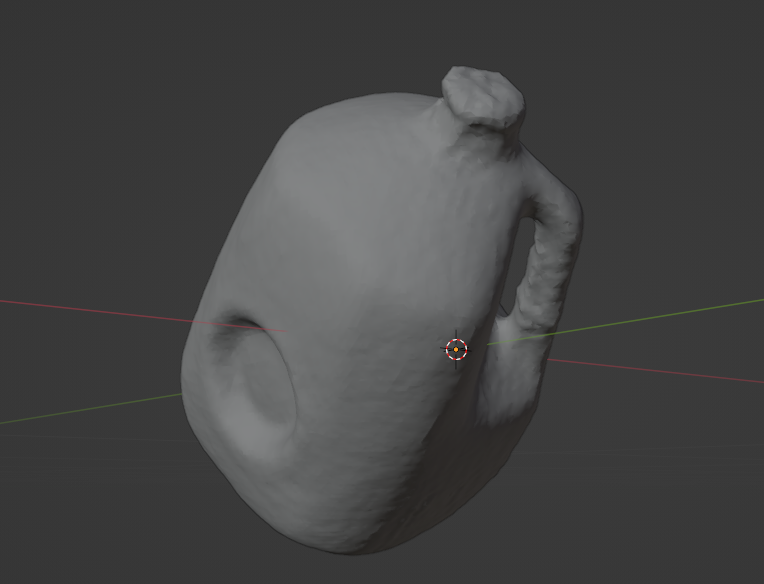
먼저 Reconstruct 된 .obj파일을 확인해보고자 합니다.
제 컴퓨터에는 Ubuntu 22.04에서 3D object를 확인할 수 있는 tool이 아직 설치되어있지 않아
Blender를 설치해주었습니다.
sudo apt install blender
터미널에 blender를 입력하여 실행시킵니다.
그리고 다음 설정을 그대로 확인을 누릅니다.

이제 .obj 파일을 불러오겠습니다.
File에서 Import, .obj 파일을 선택합니다.

그리고 결과가 있는 경로에서 mesh_cleaned.obj 를 불러옵니다.
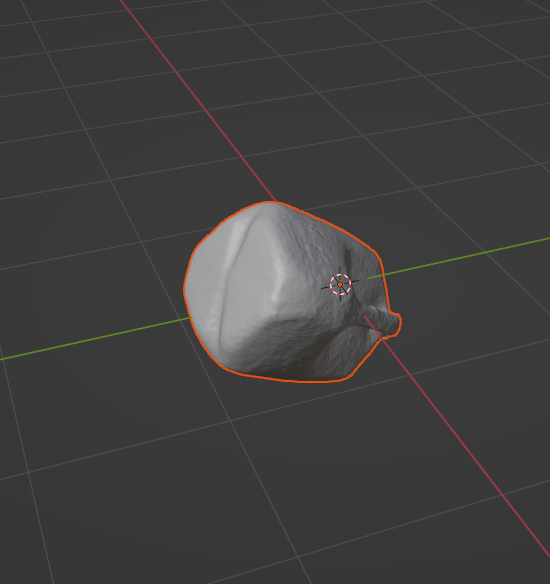
reconstruction 된 물체를 확인할 수 있습니다.
삭제하고 textured_mesh.obj 도 확인해보았습니다.
신기합니다.
일단 3D box가 존재하는 png파일은 result의 pose_vis 디렉토리에 존재합니다.
이를 비디오로 만들기 위해 다음 make_video.py 를 작성했습니다.
BundleSDF 디렉토리에 두고 사용하시면 됩니다.
필요에 따라 경로와 output_file 명, fps 등을 수정하시기 바랍니다.
import cv2
import os
import glob
def create_video_from_images(folder_path, output_file, fps):
# 사전식 순서로 .png 파일 목록 가져오기
images = sorted(glob.glob(f'result/pose_vis/*.png'))
# 이미지 목록이 비어있는지 확인
if not images:
raise ValueError("There are no .png files in the provided directory")
# 첫 번째 이미지로부터 비디오 프레임의 크기를 결정
frame = cv2.imread(images[0])
height, width, layers = frame.shape
size = (width, height)
# mp4로 내보내기 설정
out = cv2.VideoWriter(output_file, cv2.VideoWriter_fourcc(*'mp4v'), fps, size)
# 이미지를 비디오 프레임으로 추가
for image in images:
img = cv2.imread(image)
out.write(img)
# 완료 후 결과물 release
out.release()
print(f'Video saved as {output_file}')
create_video_from_images('path_to_your_images_directory', output_file = 'BundleSDF_milk.mp4', fps = 30)
이 코드를 작동시키면 .mp4 결과가 생성되는데요,
Ubuntu22.04에서 이것도 작동시켜 확인할 수가 없어
이번엔 VLC 미디어 플레이어를 설치하겠습니다.
sudo apt install vlc
Open with other application을 통해 VLC로 결과 비디오를 열면 결과를 확인할 수 있습니다.
object의 Pose를 잘 추적하네요.

제가 최종적으로 필요한 것은 realtime 추적입니다.
이것을 해결하기 위해 Github Issue를 많이 뒤져보았는데요,
기존의 CenterPose와 비교했을 때,
depth camera를 사용하여
카테고리 되지 않은 object 에 대해서 3D Pose Estimation 이 가능하고,
(이는 첫 번째 frame segmentation을 통해서 가능)
Object SLAM 이 가능하다는 장점이 있었습니다.
저는 굳이 Object SLAM 기술은 필요하지 않아서
object SLAM 을 수행하는 이 기능에 필요한 Key frame을 극단적으로 늘리는 방식으로
최대한 빠른 분석이 가능하도록 하였지만
결론적으로 real time 분석은 불가능하다는 개발자의 comment가 있었습니다.
near real-time?? · Issue #17 · NVlabs/BundleSDF
Hi @wenbowen123 I am trying to fill in the gap for my own understanding. So, your method works for 6 DoF pose of novel objects (and novel classes) that were not in training and are only shown in in...
github.com
다만 CenterPose는 학습된 Category 에 대해서만 Pose Estimation을 할 수 있다는 제한이 있지만
RGB input 만을 가지고 Real time (15fps) Pose Estimation이 가능합니다.
또한 refactoring 을 좀 한다면,
Depth camera를 통해 추가적으로 relative 한 height, width, thick 등의 값들을 상당히 정확하게 예측하게 만들 수도 있을거라 생각합니다.
여러 기술의 장점과 단점이 돋보이는 것 같습니다.
BundleSDF 예제 수행 글은 여기서 마치도록 하겠습니다.
'Research & Algorithm > Computer Vision' 카테고리의 다른 글
| Intel RealSense 를 활용한 YOLOv8 RealTime Object Segmentation (0) | 2024.01.29 |
|---|---|
| YOLOv8 으로 RealTime Object Segmentation 수행하기 (5) | 2024.01.29 |
| [논문 리뷰] BundleSDF: Neural 6-DoF Tracking and 3D Reconstruction of Unknown Objects (3) | 2024.01.24 |
| Python3 에서 Intel RealSense Camera Intrinsic Matrix 얻기 (0) | 2024.01.22 |
| CenterPose 환경 구성 및 shoes 예제 수행 (1) | 2024.01.14 |