Unknown object에 대해 3D Pose Estimation 과 Object SLAM 기술이 동시에 가능한
BundleSDF에 대해서 살짝 찍먹해보았는데요.
CVPR 2023 에서 발표된 논문입니다.
저도 완전히 이해하진 못했지만 간단하게 Input과 Output의 흐름과
사용된 방식들을 이해해보려고 했습니다.
생각보다 아직은 적용하기에는 무리가 있어보였습니다.
물론 제 실력은 훨씬 열등하지만...
그래도 아래 링크를 눌러 확인해보시면 그 기술은 굉장하다는 생각이 들었습니다.
BundleSDF: Neural 6-DoF Tracking and 3D Reconstruction of Unknown Objects
We present a near real-time method for 6-DoF tracking of an unknown object from a monocular RGBD video sequence, while simultaneously performing neural 3D reconstruction of the object. Our method works for arbitrary rigid objects, even when visual texture
bundlesdf.github.io
어떻게 이것이 가능한건지 일단은 흐름을 한 번 짚어보겠습니다.

BundleSDF는 Unknown Object 를 촬영한 RGB-D video의 각 frame과
first frame의 segment image (첫 이미지 + XMem 이용하여 전체 동영상 프레임에 대하여 생성시킴)
Camera Intrinsic Matrix만 있으면
해당 비디오에서 Segment된 target object의 Pose를 Estimation합니다.
이 과정에서 해당 물체의 3D reconstruction 파일인 .obj 파일도 생성됩니다.
물론 실시간 처리는 불가능합니다.
어떻게 이것이 가능할까요?
우선 저자가 설명한 기존 연구와의 차별점부터 설명하겠습니다.
여태까지의 6D Pose Estimation의 한계
물체의 CAD를 가지고 있다면 비디오에 해당 CAD를 입혀서
3D Pose Estimation을 하는 연구가 많이 존재했습니다.
MegaPose 가 대표적인 그 예 입니다.
그래서 어떤 새로운 물체를 정확하게 추정하려면 해당 Object의 CAD 모델이 Inference간에 요구가 되었습니다.
이러한 방식의 문제점은 사전 정보 요구성이 너무나 강하다는 것입니다.
일상생활 대부분의 물체는 그 CAD 모델을 가지고 있지 않고,
실제 물체가 항상 CAD 모델대로 생겼다는 보장도 없습니다.
Bundle SDF의 특징
Bundle SDF는 이러한 문제를 해결하기 위해 제시된 방안입니다.
다음과 같은 특징을 지닙니다.
Tracking Drift 를 최소화하여 6D Object Tracking을 수행하여 실시간성이 보장 (10Hz)
이건 실제로 도대체 어떻게 10Hz가 나오나 Github를 뒤져봤더니,
3D reconstruction 없이(학습 수행 없이) 비디오를 1초에 10프레임 처리할 수 있다는 말인 것 같습니다.
다만 XMem과의 연계성 때문에 아직은 웹캠 영상과 같은 실시간 처리는 불가능 한 것 같습니다.
이미지 프레임에서 2차원 객체 마스크만 잘 segment하면 다른 정보를 요구하지 않음 - XMem
Dynamic memory pool을 이용해 key frame을 관리하고 Pose Graph 최적화 결과를 저장
Pose Graph 최적화와 Neural Object field(NeRF 기반 3D reconstruction) 을 병렬적으로 동시에 학습
SDF 기술을 기반으로 target object의 surface를 표현
어려운 말이 많은데요 하나씩 구조를 살펴보겠습니다.
Coarse Pose Initialization
BundleSDF의 특징은 XMem을 사용하여 object masking을 하기 때문에
Initial Guess를 실패하면 Pose Tracking 을 성공적으로 수행할 수 없다는 것입니다.

들어온 이미지에 대하여 XMem을 통해 Masking 이 이루어지고
LoFTR 로 이전 프레임과 비교하여 feature matching이 이루어집니다.
LoFTR은 texture(외형적 특징)가 없거나 흐릿하더라도 matching이 가능하다는 장점이 있습니다.
이렇게 생성된 하나의 결과 frame이 memory pool 에 들어갈지 결정하게 됩니다.
Memory Pool
Correspondence를 찾아내면
우리가 이것이 key frame으로 간주해야하는지를 고려하고
이를 memory pool에 저장합니다.
(이 때 이 프레임을 memory frame이라고 합니다)

memory pool을 사용하는 이유는 뭘까요?
연속한 frame에 대해서 pose를 추정하면 pose 오차가 조금씩 발생하게 됩니다.
이러한 누적 오차가 발생하다보면,
나중에는 엉뚱한 위치를 tracking하는 tracking drift가 발생하게 됩니다.
따라서 이를 줄이기 위해 상대적인 포즈 변화를 잘 파악할 수 있는 key frame을 memory frame에 저장합니다.
항상 맨 처음 프레임은 Anchor frame (Initial guess 가 잘 이루어졌다는 전제 하에)이 되고,
그 다음부터 frame에 대해서는 모든 memory frame과 비교하여 새로운 memory frame이 될 수 있을지를 판단합니다.
보통 회전 거리를 계산하고 기존 프레임들에 비해 많이 회전되었다면 memory pool 에 저장하게 됩니다.
Pose Graph Optimization
memory frame을 가져와서 Pose Graph를 구성합니다.
frame과 frame 사이의 relative pose를 배치하여 최적의 Pose Graph를 구성해나가게 됩니다.
이는 나중에 언급될 Neural Object Field 와 함께 상호보완적으로 병렬 학습을 해나가게 됩니다.
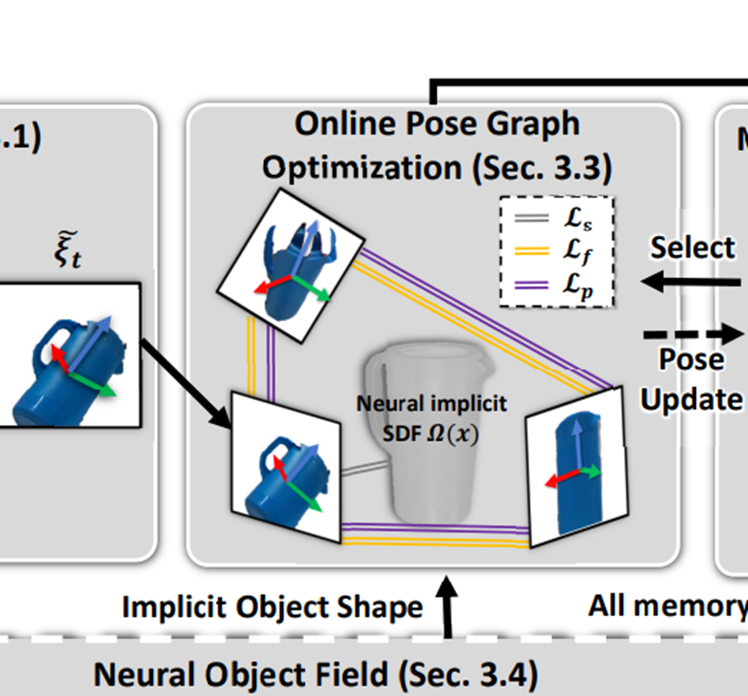
Neural object field (3D reconstruction)
Neural SDF를 얻기 위한 학습을 수행하여 Neural Object field를 도출합니다.

결과적으로 여러 시점에서 일관된 3차원 shape와 appearance를 얻을 수 있게 됩니다.
학습된 SDF로 얻을 수 있는 shape를 기반으로
pose graph optimization 를 다시 구성하여 상호보완적으로 학습해 나갑니다.
특징은 새로운 memory frame이 추가될 때 마다 짧은 training을 한다는 것입니다.
NeRF는 transformation matrix를 모르다보니 colmap으로 이를 찾는데,
여기서는 colmap 이 아닌, pose graph 최적화를 통해
이를 대체시켜 3D Construction이 가능하도록 했습니다.
Neural object field는 2가지 함수 Geometry function 과 Appearance function을 학습하고,
Depth Value 를 기준으로 appearance network 로 학습된 결과와 weight function을 이용하여
Neural Rendering을 수행합니다.
최종적으로 RGB-D video의 1st Image에서 masking 한 target object를
아래와 같이 3D reconstruction이 가능합니다.

그럼 다음 글에선 BundleSDF Github의 예제를 수행하는 과정에 대해서 작성하겠습니다.
BundleSDF (3D Pose Estimation & Reconstruction) Example 수행
BundleSDF는 RGB-D video input과 Camera Intrinsic Matrix, XMem의 Object Segmentation을 이용하여 Segment Object의 3D Pose Estimation 과 3D reconstruction 을 수행할 수 있는 방식입니다. 추가 정보는 아래 글들에서 확인하시기
cobang.tistory.com
'Research & Algorithm > Computer Vision' 카테고리의 다른 글
| YOLOv8 으로 RealTime Object Segmentation 수행하기 (5) | 2024.01.29 |
|---|---|
| BundleSDF (3D Pose Estimation & Reconstruction) Example 수행 (7) | 2024.01.24 |
| Python3 에서 Intel RealSense Camera Intrinsic Matrix 얻기 (0) | 2024.01.22 |
| CenterPose 환경 구성 및 shoes 예제 수행 (1) | 2024.01.14 |
| [논문 리뷰] CenterPose - Single-Stage Keypoint-Based Category-Level Object Pose Estimation from an RGB Image (2022 ICRA) (2) | 2024.01.14 |