최근 Object Pose Estimation 에 관해 연구를 하게 되어 작성하는 글입니다.
2022년 Nvidia Lab과 Georgia Institute of Technology 에서 ICRA에 게제한 논문이며,
CAD 모델 없이 Monocular RGB input 만으로 Category Object의 Pose Estimation을 성공적으로 수행한 논문입니다.
약칭은 CenterPose입니다.

LIN, Yunzhi, et al. Single-stage keypoint-based category-level object pose estimation from an RGB image. In: 2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022. p. 1547-1553.
CenterPose (ICRA 2022)
Abstract: Prior work on 6-DoF object pose estimation has largely focused on instance-level processing, in which a textured CAD model is available for each object being detected. Category-level 6-DoF pose estimation represents an important step toward devel
sites.google.com
GitHub - NVlabs/CenterPose: Single-Stage Keypoint-based Category-level Object Pose Estimation from an RGB Image (ICRA 2022)
Single-Stage Keypoint-based Category-level Object Pose Estimation from an RGB Image (ICRA 2022) - GitHub - NVlabs/CenterPose: Single-Stage Keypoint-based Category-level Object Pose Estimation from ...
github.com
https://arxiv.org/pdf/2109.06161.pdf
최근 이보다 더 발전된 6D Pose Estimation 논문들이 더 많이 나왔지만,
일단 RGB input 과 categorized 만으로 Object Pose Estimation 을 성공한 CenterPose 를 공부하고 다른 논문들을 공부하도록 하겠습니다.
제가 이 분야에 대해 아직 지식이 많이 부족해서,
잘못 해석한 부분이 많이 존재할 수도 있습니다.
Approach
전체적인 과정부터 다루도록 하겠습니다.
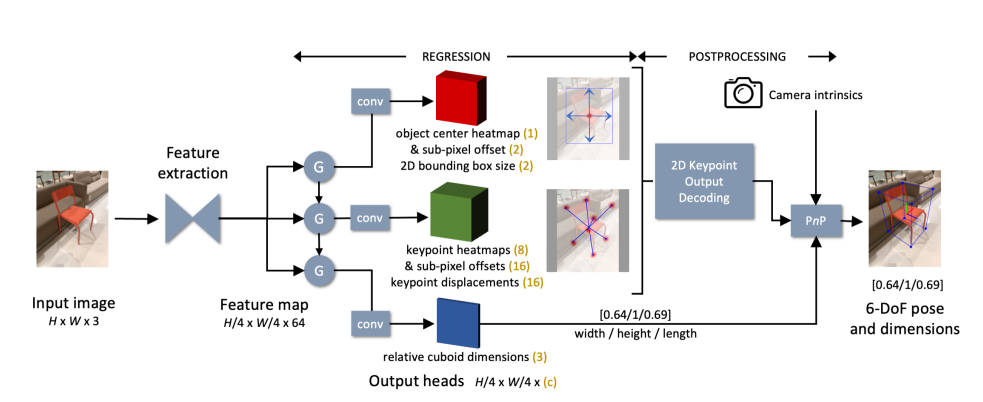
Category-level object pose estimation 방법은 위 그림에 나타나 있습니다.
이전의 correspondence-based method 선행 연구들을 따라
3D bounding cuboid의 모서리들의 2D image projection을 예측하고,
이어서 PnP(Perspective-n-Point)를 사용하여 Pose를 계산합니다.
본 연구는 CenterNet 아키텍처를 기반으로 한 최근 연구들에 영감을 받아,
single-stage network를 사용하여 모든 예측을 수행합니다.
여기에는 PnP에 필요한 relative dimensions of the cuboid 도 포함됩니다.
2D 입력으로부터 3D 구조 정보를 추론하는 어려움을 완화하기 위해,
convGRU 모듈을 사용하여 난이도가 증가하는 순서대로 출력을 예측할 것을 제안하였습니다.
일단 무슨 말인지 잘 알아들을 수가 없는데, 차분히 접근해봅시다.
Architecture Design
전체 과정은 선행 연구로부터 유사하게 가져왔습니다.
해당 논문입니다.
GAO, Tianze; PAN, Huihui; GAO, Huijun. Monocular 3D object detection with sequential feature association and depth hint augmentation. IEEE Transactions on Intelligent Vehicles, 2022, 7.2: 240-250.
Monocular 3D Object Detection With Sequential Feature Association and Depth Hint Augmentation
Monocular 3D object detection, with the aim of predicting the geometric properties of on-road objects, is a promising research topic for the intelligent perception systems of autonomous driving. Most state-of-the-art methods follow a keypoint-based paradig
ieeexplore.ieee.org
먼저 해상도가 H×W×3인 RGB 이미지를 입력으로 받습니다.
원본 이미지는 필요에 따라 재조정되어 W = H = 512 px 가 됩니다.
DLA-34 [34]를 backbone 네트워크로 채택하였고, upsampling과 결합하여 사용합니다.
[34] F. Yu, D. Wang, E. Shelhamer, and T. Darrell, “Deep layer aggregation,” in CVPR, 2018, pp. 2403–2412.
DLA-34는 네트워크의 서로 다른 레벨에서 특징들을 추출합니다.
이는 상위 레벨과 하위 레벨 간의 정보 흐름을 강화하여, 더 효율적인 특징 학습을 가능하게 합니다.
이 backbone 네트워크는 hierarchical aggregation connection이 변형 가능한 convolutional layer에 의해 확장됩니다. [35]
[35] X. Zhu, H. Hu, S. Lin, and J. Dai, “Deformable Convnets v2: More deformable, better results,” in CVPR, 2019, pp. 9308–9316.
backbone 네트워크는 공간 해상도가 H/4×W/4부터 H/32×W/32까지
다양한 multiple intermediate feature maps을 생성하며,
이들은 최종적으로 단일 H/4×W/4×64 출력으로 만들어지게 됩니다.
네트워크는 총 일곱 개의 출력 head를 세 개의 그룹으로 배치합니다.
각 출력 head에는 해당 convGRU( Convolutional Gated Recurrent Unit ) 모듈의 출력을 처리하기 위해
256 채널을 가진 3×3 convolution layer에 이어 1×1 convolution layer가 사용됩니다.
출력은 dense heatmaps 또는 regression maps으로 예측되지만,
감지된 object center 와의 일치에 따라 sparse하게 접근됩니다.
각 branch를 하나씩 살펴보겠습니다.
Object Detection Branch
위 네트워크의 주요 출력은
감지된 object의 2D bounding box의 peak가 중심에 표시된 object center heatmap 입니다.
detected 된 object의 2D bounding box에 대해 중심점을 표시합니다.
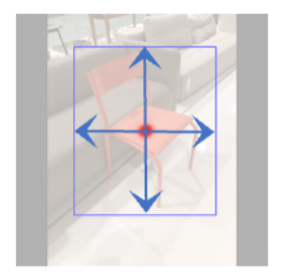
이제 다른 output map들은 이 object center를 이용하여 접근이 이루어집니다.
즉, object center heatmap에서 (c_x, c_y) 위치에 peak가 발견되면,
다른 나머지 출력들에서 (c_x, c_y)의 값들이 이 object 와 연관이 됩니다.
heatmap output resolution에서 발생하는 discretization 오차를 복구하기 위해,
local 2D object center sub-pixel offset map[16]을 이용합니다.
[16] X. Zhou, D. Wang, and P. Krahenb ¨ uhl, “Objects as points,” ¨ arXiv preprint arXiv:1904.07850, 2019.
이 기법은 object의 중심이 픽셀 격자 사이에 위치할 경우,
이를 더 정확하게 표현하기 위해 사용됩니다.
Local 2D object center sub-pixel offset map은
Object의 중심에 대한 세부적인 (sub-pixel 수준의) offset 정보를 제공합니다.
즉, Object 의 중심이 정확히 어느 픽셀에 속하는지,
그리고 그 픽셀의 중심으로부터 얼마나 떨어져 있는지를 나타냅니다.
Training 시에는 사용한 Objectron dataset이 2D bounding box annotation을 제공하지 않았기 때문에,
이를 정사영된 실제 3D bounding box의 꼭짓점을 포함하는 가장 작은 축의 직사각형으로 정의해서 학습을 시켰다고 합니다.
Keypoint Detection Branch
이 네트워크는 Training시 3D box의 vertex를 이미지에 정사영 시킨 좌표를 얻기 위해 다음 2가지 방법을 사용합니다.
- 2D keypoint 변위 벡터들을 3D bounding box 의 center point를 이용하여 유도합니다.
- 직육면체 꼭짓점 8개의 2d 좌표를 나타낸 8 keypoint heatmaps set을 얻어냅니다.
이러한 peak들은 다른 네트워크 출력들처럼 object’s center의 좌표에서 접근되지 않습니다.
2D bounding box의 크기에 따라 결정된 variance를 가진 실제 keypoint coordinates 는
Gaussian Kernel (centered at the ground truth) 에 의해 생성됩니다.
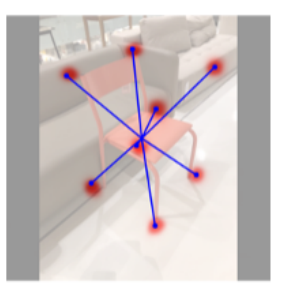
위에서 언급한 것처럼, 여기서도 discretization error를 완화하기 위해
각 꼭짓점에 대한 local 2D keypoint sub pixel offset 을 이용합니다.
Cuboid Dimensions Branch
Category-level pose estimation은 우리가 특정한 target object에 대한 CAD 모델을 사용할 수 없다고 가정하기 때문에
3D cube의 width, heigth, length 등의 상대적인 값들을 예측하기 위하여 final output branch 를 대신 사용합니다.
위 상대적인 값은 monocular RGB 이미지에서 absolute depth를 추정할 필요성이 없도록 만들어줍니다.
또한, 이는 근본적으로 잘못된 것이 absolute depth는 절대 정확하게 예측할 수 없습니다.
(예를 들어, 우리가 보고 있는 것이 실제 크기의 의자인지 장난감 의자인지 알 수 없습니다.)
상대적인 값은 네트워크를 different camera intrinsic으로 얻은 이미지에 적용할 수 있도록 하며,
이 덕분에 네트워크를 다시 훈련할 필요가 없습니다.
일상생활에서 많은 target object들이 땅에 놓일 때 표준적인 방향을 가지고 있기 때문에,
위쪽(y) 축을 주축으로 선택합니다.
실제 scale label은 (x/y, 1, z/y)로 간주되며,
x/y 및 z/y 비율은 네트워크에 의해 추정됩니다.
실제에서는 물체가 다양한 aspect ratio를 갖기 때문에 각각의 비율을 직접 regress합니다.
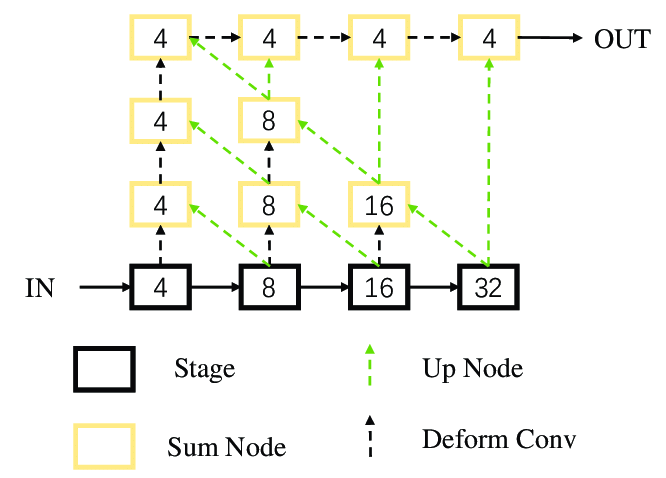
convGRU Feature Association
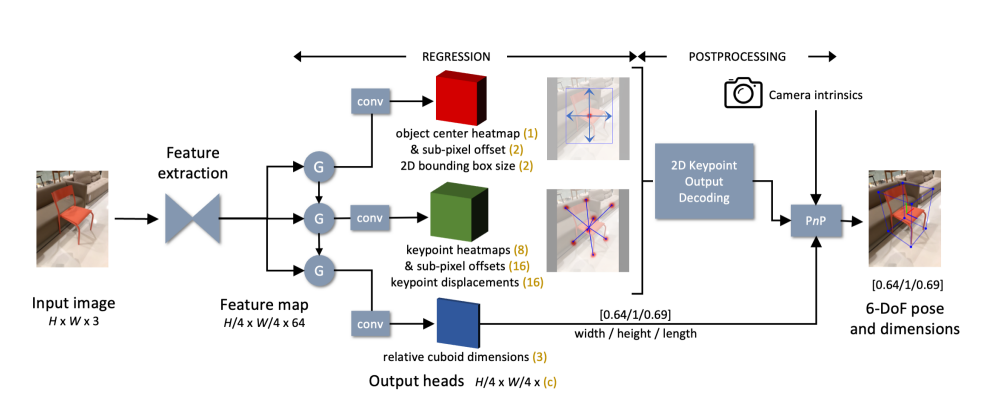
직관적으로, 위 그림과 같이 네트워크를 세 그룹으로 나누었습니다.
- object center heatmap, object center sub-pixel offset, 2D bounding box size
- keypoint heatmaps, keypoint sub-pixel offsets, x-y displacements to keypoint
- relative cuboid dimensions
마지막 그룹 3은 3D 구조가 2D 외형에서 암시적으로 추론되어야 하기 때문에 추정하기 가장 어렵습니다.
본 연구에서는 object center point와 2D bounding box가 추정되면 키포인트를 더 쉽게 찾을 수 있다고 가설을 세웠으며,
마찬가지로 키포인트가 찾아진 후에는 bounding box dimension를 더 쉽게 예측할 수 있다고 가설을 세웠습니다.
이 그룹화 전략은 recurrent neural network에서 이전 그룹의 output이 현재 그룹의 input으로 사용되는 순차적인 방식으로 사용되었습니다.
입력 이미지 I가 주어지면, i번째 출력 (i = 1, ..., 7)은 다음과 같이 표현됩니다.
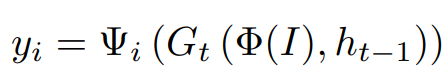
여기서는 Φ(I) 는 backbone network에서의 feature map을 나타내고,
Gt(·) 는 time step t에서의 GRU를 나타내며,
(time step은 계산되고 있는 그룹을 의미합니다. t = 0, 1, 2, 3)
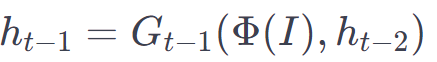
h_t-1 은 이전 타임스텝에서 생성된 output을 나타내고, h0 = 0 입니다.
Ψ_i 는 i번째 출력을 위한 전체 convolutional network 입니다.
본 연구는 single-layer convolutional GRU network를 채택하며,
여기서 convGRU의 모든 convolution layer는 stride = 1, kernel size = 3, output channels = 64 로 설정됩니다.
2D Keypoint Output Decoding
학습된 네트워크에 어떤 입력이 들어왔을 때,
각 네트워크의 출력은 다음과 같은 방식으로 디코딩되고 assemble됩니다.
먼저, 3×3 max pooling operation ( feature map downsampling) 이 heatmap of the 2D object center에 적용됩니다.
각각 감지된 중심점에 대해, 중심점 기반의 2D x-y 이동을 이용한 키포인트 위치가 주어집니다.
다음으로, heatmap-based의 키포인트 위치는 해당 heatmap에서 2D object bounding box의 margin 내에서 높은 신뢰도의 peak를 찾아 추출됩니다.
키포인트 위치의 추정치는 sub-pixel offset에 따라 조정되고,
추정된 relative cuboid dimension과 함께 PnP의 Levenberg-Marquardt 버전 [36]에 입력됩니다.
[36] Y. I. Abdel-Aziz, H. M. Karara, and M. Hauck, “Direct linear transformation from comparator coordinates into object space coordinates in close-range photogrammetry,” Photogrammetric Engineering & Remote Sensing, vol. 81, no. 2, pp. 103–107, 2015
PnP (Perspective-n-Point) 는 3차원 공간에서의 점들과 그에 해당하는 2차원 이미지 상의 점들 간의 대응 관계를 바탕으로,
카메라의 포즈(위치와 방향)를 추정하는 방법입니다.
PnP의 Levenberg-Marquardt 버전은 PnP에 Levenberg-Marquardt 최적화 알고리즘을 사용한 것으로
PnP를 수치적으로 최적화합니다.
이를 통해 해를 더 정확하고 빠르게 찾을 수 있습니다.
Loss Function
본 연구는 중심점과 keypoint heatmap에 대해
Lpcen과 Lpkey의 penalty-reduced focal losses[37]을 point-wise manner으로 사용합니다.
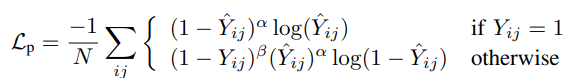
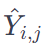
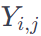
heatmap (i, j) 에서의 ground truth 값
,
center sub-pixel offset loss, Loff는 L1 loss 사용하여 계산됩니다.
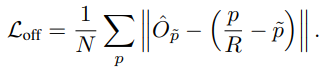
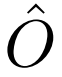
는 predicted offset을 의미하며,
p 는 ground truth center point
R 은 output stride
low-resolution equivalent of p
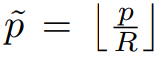
로 표현됩니다.
keypoint subpixel offset loss, Loffkey 역시 유사하게 계산됩니다.
2D bounding box size, Lbbox,
keypoint displacement loss, Ldis,
relative cuboid dimensions loss, Ldim도 각각의 label 값에 대해 L1 Loss을 사용하여 계산됩니다.
전체적인 Training 목표는 위에서 언급한 7가지 loss 항목의 weighted combination입니다.
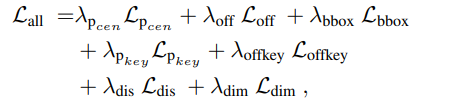
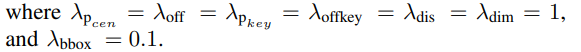
Implementation detail
네트워크는 4개의 NVIDIA V-100 GPU에서 ImageNet의 pre-trained weight 를 사용하여 batch size 32로 140 epochs 동안 training되었습니다.
Data augmentation으로는 random flip, scaling, cropping, color jittering을 포함시켰습니다.
우리는 initial learning rate가 2.5e-4인 Adam을 Optimizer로 선택했으며,
각각 90과 120 epochs에서 learning rate를 10배 감소시켰습니다.
한 category를 훈련하는 데 평균 36시간이 소요되었으며
(카테고리에 따라 8천에서 3만 2천 개의 훈련 이미지 사용)
Inference 속도는 NVIDIA GTX 1080Ti GPU에서 약 15 fps입니다.
이는 CenterPose GitHub를 통해 수행해볼 수 있으며,
실제로 이 학습된 모델을 사용해보는 글을 작성할 예정입니다.
EXPERIMENTAL RESULTS
Data Set
Objectron dataset [15]은 monocular RGB category-level 6-DoF object pose estimation을 위한 새롭게 제안된 benchmark입니다.
이 dataset은 15,000개의 주석이 달린 비디오 클립과
400만 개가 넘는 주석이 달린 frame으로 구성되어 있습니다.
Object는 bikes, books, bottles, cameras, cereal boxes, chairs, cups, laptops, shoes의 9가지 category에 속합니다.
GitHub - google-research-datasets/Objectron: Objectron is a dataset of short, object-centric video clips. In addition, the video
Objectron is a dataset of short, object-centric video clips. In addition, the videos also contain AR session metadata including camera poses, sparse point-clouds and planes. In each video, the came...
github.com
각 객체는 3D bounding cuboid로 주석이 달려 있으며, 이는 카메라에 대한 객체의 위치와 방향뿐만 아니라 cuboid dimension를 설명합니다.
추가 metadata에는 camera pose, sparse point cloud, surface plane이 포함되며,
후자는 객체가 ground 평면에 놓여 있다고 가정하여 absolute scale factor를 제공합니다.
Training을 위해, original video를 15 fps로 downsampling하여 프레임을 추출합니다.
Test를 위해, dataset의 official release에서 각 category의 모든 test sample을 평가하였습니다.
Metrics
Objectron dataset을 따라, 3D detection과 object dimension estimation을 평가하기 위해
MobilePose[14]에 의해 제안된 3D IoU metric의 Average Precision(AP)를 50%의 threshold로 사용합니다.
[14] T. Hou, A. Ahmadyan, L. Zhang, J. Wei, and M. Grundmann, “MobilePose: Real-time pose estimation for unseen objects with weak shape supervision,” arXiv preprint arXiv:2003.03522, 2020.
Mean pixel error metric은 추정된 포즈와 ground truth pose에 대한 3D bounding box keypoint의 2D projection 간의 mean normalized distance를 계산합니다.
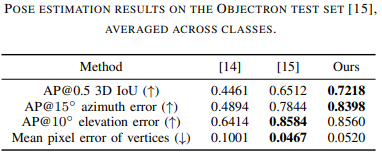
viewpoint estimation을 위해, azimuth와 elevation의 AP를 각각 15°와 10°의 threshold로 적용하여 비교합니다.
표에 첨부된 숫자는 3D IoU를 극대화하거나 pixel projection error를 최소화하는 instance입니다.
relative dimension prediction에 대한 비교를 위해,
본 연구는 모든 prediction에 걸쳐 relative dimension의 relative error를 계산하는 mean relative dimension error를 사용합니다.
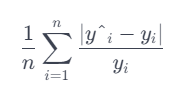
y_i hat은 denotes the prediction
y_i 는 ground truth 를 의미합니다.
Category-Level 6-DoF Pose and Size Estimation
여기서는 본 연구에서 제안한 방법을 single-stage MobilePose [14]와
a two-stage network [15]와 같은 두 가지 최신 방법과 비교합니다.
[15] A. Ahmadyan, L. Zhang, A. Ablavatski, J. Wei, and M. Grundmann, “Objectron: A large scale dataset of object-centric videos in the wild with pose annotations,” in CVPR, 2021, pp. 7822–7831.
이들은 Objectron 데이터셋에 대해 비교가 가능한 유일한 방법들입니다.

각 class에 대한 3D IoU 결과는 위 표에 나타나 있습니다.
아래 그림은 각 class에 대해 Ground truth와 비교한 정성적인 결과입니다.

또한, 아래 비디오는 본 연구의 시스템으로 추정된 위치와 방향을 사용하여
한 쌍의 신발을 정리하는 로봇을 보여줍니다.
https://drive.google.com/file/d/11KFvEiSXpL8T1lTTpb7lMabOZCKx-Hml/view
object_arrangement.MP4
drive.google.com
신발 한짝을 이미 집어두고, 놓여 있는 신발의 방향에 맞게 신발을 놓는 모습입니다.
이 실험의 단순화를 위해서 물체의 size를 제공했다고 합니다.
본 연구의 방법은 모든 Metric에서 MobilePose를 크게 능가하며,
two-stage network 는 2D projection의 일부 경우에서 더 나은 성능을 달성하지만
3D IoU metric에서는 본 연구보다 낮습니다.
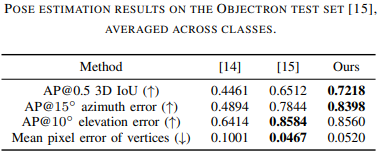
그들의 two-stage structure는 keypoint detector가 더 나은 keypoint location performance을 위해 더 높은 이미지 해상도에서 작동하도록 허용하지만,
끝까지 훈련하는 end-to-end training 능력과 더 많은 category로 빠르게 확장하는 fast scale-up 능력에 제한을 두고 있습니다.
이는 두 네트워크가 독립적으로 훈련되어야 하기 때문입니다.
Different strategies for 2D Keypoint Output Decoding
기존의 keypoint-based object pose estimation 방법들 대부분은
2D keypoint detection을 위해 heatmap 또는 displacement 표현을 채택합니다.
여기서는 본 연구는 2D keypoint output에 대한 다섯 가지 다른 후처리 방법을 비교하기 위한 실험을 하였습니다.
1. Displacement, ignores the heatmap
2. Heatmap, ignores the displacement
3. Distance는 displacement 또는 heatmap에서 더 신뢰할 수 있는 점을 선택하려고 시도하는 [16]과 유사한 heuristic을 구현
[16] X. Zhou, D. Wang, and P. Krahenb ¨ uhl, “Objects as points,” ¨ arXiv preprint arXiv:1904.07850, 2019.
4. Sampling은 [38]에서 영감을 받아 각 keypoint에 대해 heatmap peak 추정치와 displacement 예측에 Gaussian mixture model을 적용한 다음 N개의 점(N = 20)을 샘플링하여 가능한 pose의 분포를 획득
[38] M. A. Lee, C. Florensa, J. Tremblay, N. Ratliff, A. Garg, F. Ramos, and D. Fox, “Guided Uncertainty-Aware Policy Optimization: Combining learning and model-based strategies for sample-efficient policy learning,” in ICRA, 2020, pp. 7505–7512.
5. 본 연구에서 제안한 방법은 displacement 와 heatmap 모두를 유지합니다.

위 표에서 보여지듯이, 본 연구에서 제안한 결합 방법(displacement + heatmap)은
단일 표현(displacement or heatmap)보다 더 우수하며,
추가적인 처리(예: Distance[16] 또는 Sampling[38])가 필요하지 않습니다.
따라서 정확도와 효율성을 균형있게 하기 위해,
본 연구에서는 이 combined representation을 사용하였습니다.
Different Strategies for Cuboid Dimension Prediction
여기서는 cuboid dimension prediction에 대한 다양한 전략에 대한 실험을 제시하고,
본 연구의 방식의 성능이 우수함을 입증합니다.
이는 정확한 스케일 예측의 중요성을 더욱 드러내고,
어려운 경우를 위한 순차적 특징 연결 모듈(convGRU)의 가치를 입증합니다.
본 연구는 시스템의 다음 변형을 테스트했습니다.
1. Keypoint lifting, 이는 MobilePose에서 제안된 postprocessing 부분을 재구현하여, 2D projected cuboid keypoint만을 사용하여 최종 포즈를 획득
2. convGRU 없음, 본 연구에서 제안한 방법에서 convGRU layer를 제거
3. convGRU 포함한 본 연구에서 제안한 방법
4. Oracle, ground truth 3D aspect ratio(relative dimensions)에 대한 접근 권한이 있는 방법
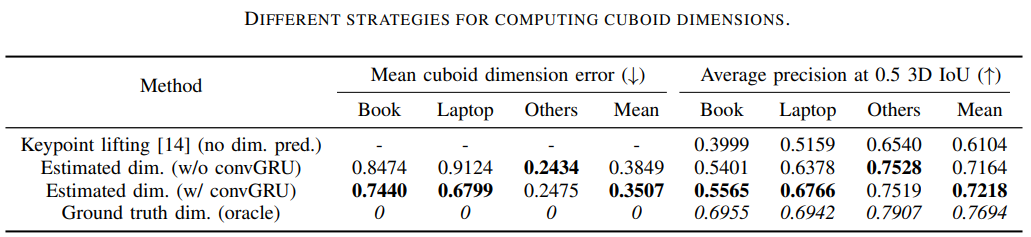
결과는 위 표에 나타나 있으며, 결과에 가장 큰 차이가 있는 두 특정 카테고리(책과 랩탑)를 분리했습니다.
결과는 3D IoU 결과와 해당 mean cuboid dimension error간의 strong relationship을 나타냅니다.
다른 Category(”Others")에서는 성능이 크게 다르지 않으며,
그들의 cuboid dimension prediction도 마찬가지입니다.
이러한 instance들은 similar aspect ratio를 가지고 있습니다.
(예를 들어 병과 같이 추정하기 쉽습니다.)
반면에, 책과 laptop 카테고리는 더 고려해야할 것이 많습니다.
책의 두께가 다양하며
노트북은 뚜껑이 열려 있는지 닫혀 있는지에 따라 다른 모드를 보이기 때문입니다.
제안된 convGRU module은 cuboid dimension 예측을 개선하고, 더 나은 3D IoU 결과로 이어졌습니다.
또한, ground truth dimension이 있는 oracle이 가장 좋은 결과를 달성했으며,
MobilePose의 간소화된 EPnP 변형을 사용할 때 성능이 저하되었는데,
( EPnP (Efficient PnP) - 효율적인 계산을 위해 설계된 PnP의 변형으로, 더 많은 점들을 효과적으로 처리)
이는 monocular RGB 입력에서 categorylevel pose estimation을 위한
relative dimension 예측이 이 문제를 해결하는 데 중요하다는 것을 보여주는 근거입니다.
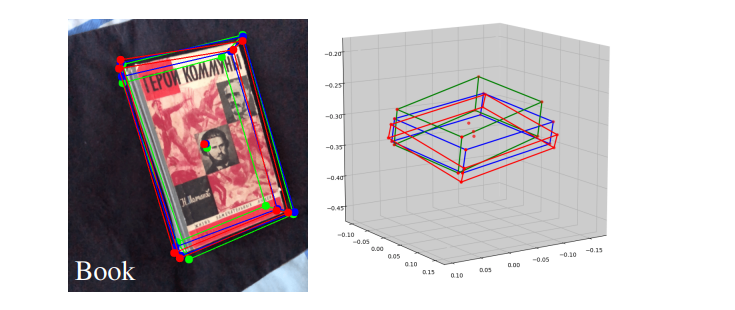
위 그림은 particular 예시를 사용하여 convGRU(파랑)가 convGRU 없이(빨강) 비교했을 때 객체의 3D aspect ratio (relative dimensions)를 검색할 수 있는 능력을 보여줍니다.
두 2D keypoint 모두 정확해 보이지만, scale 예측이 다르며,
이로 인해 3D IoU가 개선됩니다.
(convGRU 사용 시 0.5059 : convGRU 미사용 시 0.3204)
정리
Object Pose Estimation 관점에서 크게 보면 CenterPose는
다른 접근 방식과 달리,
단순한 RGB Image input 만으로도 Categorized 된 Object에 대해
Single Stage로 빠르게 Training과 Inference 가 가능하다는 장점이 있습니다.
유사 연구와 비교해보면,
3D bounding box Dataset 인 Objectron을 이용하여
single-stage MobilePose 와 a two-stage network의 두 가지 최신 방법과의 성능을 비교하고,
본 연구가 Objectron DataSet에 대해 최고의 성능을 냄을 입증하였습니다.
또한, 정확한 cuboid dimension 예측의 중요성을 보이고,
다양한 aspect ratio를 가진 어려운 경우에 대한 정확도를 더욱 향상시키기 위해
convGRU 순차적 연결(이전 timestep 네트워크의 output이 다음 timestep의 input이 됨)을 사용한 것이 특징입니다.
two-stage network가 Training과 Inference 속도가 느려 일반화하기 어렵다는 단점을 극복할 수 있는 것도 장점입니다.
이 논문을 통해 전체적인 6D Pose Estimation 방법에 대해 이해하고,
GitHub를 통해 실제 6D Pose Estimation 실습을 쉽게 수행해볼 수 있었습니다.
고가의 Depth camera가 없어도 가능하니 장점이 있는 방법이라고 생각합니다.
다만 Categorized 되어 있기 때문에
만약 다른 물체를 시도하고 싶다면 별도의 Dataset과 training 과정이 필요할 것입니다.

'Research & Algorithm > Computer Vision' 카테고리의 다른 글
| Python3 에서 Intel RealSense Camera Intrinsic Matrix 얻기 (0) | 2024.01.22 |
|---|---|
| CenterPose 환경 구성 및 shoes 예제 수행 (1) | 2024.01.14 |
| Intel RealSense 카메라 + YOLOv8 을 이용한 object 거리 추출 (0) | 2024.01.12 |
| Intel Realsense를 이용한 Python openCV 영상 처리 (1) | 2024.01.10 |
| Jetson Nano에서 yolov7 SORT를 이용한 실시간 영상 분석 (3) | 2024.01.06 |